






药物研发是一门试验科学,我们从无数个分子中挑出一个能解决某种人类疾病的分子仿佛是大海捞针。
除了传统的靶点发现、分子筛选的技术,近年来随着如AlphaFold 2这些新工具、新平台的赋能、化学蛋白质组、单壁细胞筛选等底层技术的发现到成熟以及大数据的积累和算法的逐渐突破。
是否有什么新的机遇来改变这一现状?是否有能突破传统药物研发中简单模型且利用新的技术来实现更贴近体内环境的药物分子和蛋白之间的相互作用模拟?中国新一代Biotech公司如雨后春笋一般涌现,我们做新药有没有优势?行业是否迎来了系统性的新的机会?
近期,蓝驰创投在线上开展了主题为「超越”简单模型”驱动的药物研发新变革」的Bio2X系列生物主题沙龙,蓝驰创投与深势科技、新樾生物、科途医学和礼达先导,围绕AI for Science、活细胞药物筛选、表型筛选与化学蛋白质组等前沿技术,交流了药物研发模式创新。
AI for Science以及其新范式
深势科技创始人兼CEO 孙伟杰
AI for Science指我们用AI先去解决事物底层运行的科学问题,再进一步解决这些科学问题所映射的工业问题。
它和过去AI for Industry模式的最直接的区别是,过去AI for Industry是依赖行业发展积累大量行业数据,再用这些数据训练AI模型从而抽取一个高价值的规律,然后再进一步做一些推演来解决实际问题,生命科学领域的人类基因组工程也是类似这样的研究范式。
药物、材料研发这些领域面临的一个很重要的问题是,我们看上去的海量数据相比于背后所要解决的高维问题而言,是微不足道的,数据和问题之间形成了比较大的不对称性。
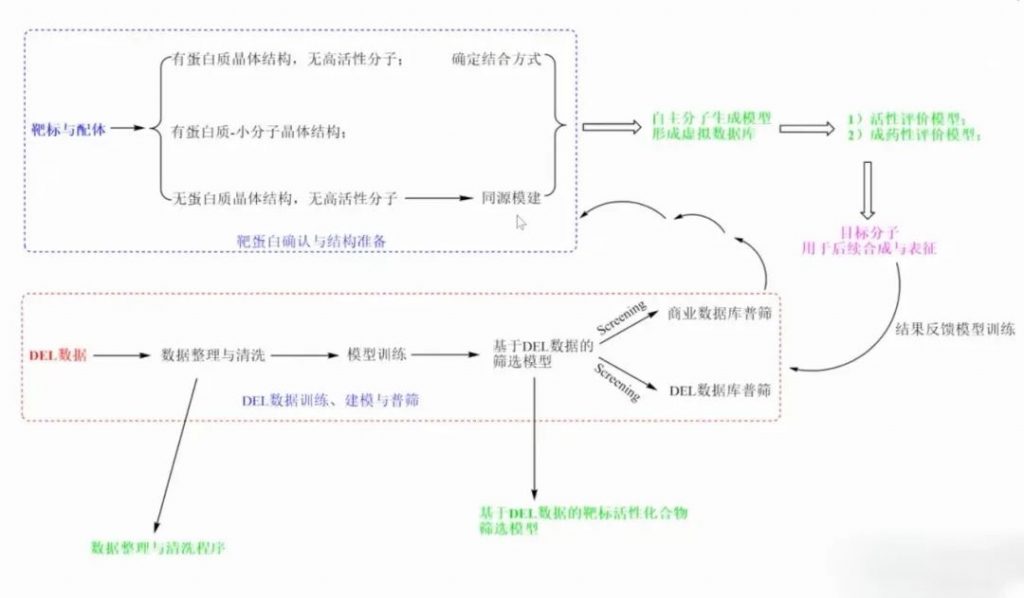
在这样的这个场景下我们就可以运用AI for Science的逻辑:虽然我们在药物设计的领域里面数据少,但科学家们可以对药物、材料底层运作的一系列物理、化学、生物的原理进行抽象,得到一系列的科学问题或者形成一系列行之有效的原理,我们用AI去学习这些科学原理或者直接去解决这些科学问题,再进一步去解决像药物研发、材料研发这样的实际问题。
AI for Science新范式主要有两种方法,一种是当事物底层运行的科学原理比较明确,比如能够把它抽象为比较明确的物理问题,那我们就可以用AI去尝试学习物理模型和求解物理方程。
另外一种是我们积累了一些科学数据,但数据很少,比如蛋白质结构预测这样的领域有一些数据,大概是20万个,但实际上我们已经测出来的蛋白质序列有超过50亿个,这个数据量和背后映射的真实问题之间存在严重不对等,我们相应的解决方案是一系列的小样本学习和数据生成。
DEL活细胞筛选技术与AI的结合
新樾生物副总经理 金锋
DNA编码化合物库(DEL)技术从单抗发现技术中获取灵感,通过PCR测序技术将获得的DNA标签和小分子的结构一一对应,可以比较快速、低成本找到蛋白高亲和力的小分子。主要分为两个部分:一个是建库,另一个是筛选。然而有一些膜蛋白难以纯化,无法用传统的DEL技术筛选与之结合的小分子。
DEL活细胞筛选技术可运用于基于活细胞的筛选,无需靶蛋白的表达与纯化,相比前一代的生化模型,基于活细胞的筛选更接近体内真实环境,从而使得筛选成功率更高。
基于创新疾病模型的表型筛选和药物发现
科途医学科技有限公司创始人 孙志坚
疾病模型领域近年来有很大的技术进步,像类器官等技术的发展,让很多以前无法建模的疾病可以得到很好的模型建立。
从模型技术本身可以看到有很多的疾病现在严重缺乏模型或者没有细胞模型,而且我们现在越来越关注一些不可成药的药物开发、一些少见突变的模型和各种各样靶向药耐药后的模型开发。
这些疾病模型涉及的领域不光是在前端的Discovery,在Transition和Development以及Preclinical阶段都有很多应用。
比如在Discovery中的靶点发现,靶点是非常珍贵的,现在统计整个人类的靶点大概有600-1500个,真正好的靶点是凤毛麟角的。85%的公司的靶点都是高度重叠的。这些靶点通常有很多不可成药,大概75%的靶点集中在激酶、CPGR和蛋白酶。
类器官可以结合最新的CRISPR技术等,进行基因改造,结合疾病模型本身所携带的背景特征,高效地提供靶点筛选、靶点发现的过程。
还有很多因为很难看到患者、细胞模型没有建立起来的病例,包括一些现在的靶向药上市之后耐药的模型的机制,同样值得通过这个模式去开发。包括以类器官库去扩展人群多样性的分析,也让我们对疾病可以有更加深层次的理解。
新药研发的技术演化超越“简单模型”
礼达先导创始人兼CEO 倪锋
药物研发从实验台到临床的过程,技术的演化趋势是要超越“简单模型”,尽量多的去获取准确和全面的信息,从而帮助前期做决策。从大尺度计算模拟到活细胞蛋白DEL再到类器官模型,这些都是不断往复杂的生物体系更进一步。
新药发现是一个非常繁琐的过程,是我们把所有的化学分子空间跟生物靶点空间匹配的过程,最大的痛点是成功率低。化学分子空间相对比较丰富,至少可能有10^60的分子,其中包括天然产物分子、人工合成分子、组合分子库和虚拟分子库等。遗憾的是生物靶点空间相对比较有限,从目前来看里面只有蛋白靶点和核酸靶点。
主要的应对策略之一是不断提高匹配的效率。从高通量筛选到虚拟筛选再到今天的DEL库筛选,我们都是在不断提高“一个研究对象vs多个研究对象”的过程。实现“多对多”是我们未来主要的方向。最重要也是最难的地方是最前端,一开始瞄靶多花点时间可能后面会轻松一些。
第二个策略是拓展可成药靶点空间。现在国内的行业现状停留在存量靶点思维,假如能够切换到增量靶点思维就能够有更多的投入在疾病认知和生物学认知,离first in class会更接近一点。我们有非常大的空间值得去探索。
QA Part 1
Q:大家怎么来看待这些难成药和靶点药物的开发?大家怎么看待这个领域技术的发展以及未来的前景?
孙伟杰(深势科技):难成药、靶点药最大的特点是难,最关键一点是要理解清楚靶标到底为什么难。一种是微观的机制难,其次比如难成靶标在生物通路上大家的理解还不够深刻,它和疾病的关系还没有充分的建立。如果想要系统性地解决靶标的问题,还是要以靶标为基础,把他的生物机制分析更清楚,然后再去选择最适合攻克这个靶标的模型。
孙志坚(科途医学):从我的个人理解来讲,分两点:1.我们要理解这些靶点所处的生物学环境。因为我们治疗的不是一个靶点而是一个疾病,所以我们可以充分提高对于疾病或者生物学的理解来试图寻找解决的方案。2.我们能够实现的工具是什么。现在可能会有更多的手段,把一些不可靶向的药物变成可以靶向的药物,这都是基于我们对生物学的理解或者工具的提升,来进一步拓展我们的能力。
倪锋(礼达先导):把一个靶点能做成药有三个方面:生理、病理和药理。现在说的不可成药或者难成药大部分都是在做药的过程中不可行,但随着工具和技术的出现,慢慢有可能把以前不行的变成可行的。两个趋势:1.在罕见病上突破,细分后可以先解决掉一些难成药的问题。2.化学空间的角度。天然产物本身是随着人类或者地球环境一起进化出来的,所以它更有可能跟生物的靶点产生一些相互的作用。如果能从分子化学里去发现活性或者疗效果并且研究清楚其中的靶点,有可能我们就可以为有些难成药的靶点找到一把钥匙。
QA Part 2
Q:我们在实验中如何能够获得质量的数据,前沿的生物技术如何能够有效的和AI相结合从而更充分的利用我们高质量、稀缺性的数据?
倪锋(礼达先导):对以实践背景出身的从业者来讲,我们是想要超越人工获取数据的效率和稳定性,所以要营造一个平台快速用一些前沿的技术来实现自动化。新技术是掌握在少数早期参与技术开发的人的手里,很难快速的推广和服务,并且让其他行业合作伙伴能够一起来共享数据。因此我认为如果能形成这样一个平台能够借助自动化来供给数据,让大家在数据基础上进行场景的开发,将有助于生物医药的基点前夜快速跨过去。
孙志坚(科途医学):数据最关键的是“关联”。临床或者疾病是非常复杂的,如何去建立这种关联,比如一个人用了什么药后产生了什么样的临床效果,这就是建立了一个关联。但这种关联会严重限制临床实验数据的大小,如果要进一步放大数据的量就要进行模型分析。另外一个维度是建立其他功能性的数据,中间的逻辑是同一个生物个体或同一个生物细胞模型,建立这种关联之后,还涉及到一个数据质量的问题。我们需要对药理或者功能性情况进行选择,尽量实现它的高通量。结合AI可以对未来的一些治疗或者开发产生非常大的价值。我们可以通过一些分子层面的变化和数据库之间的关联,建立其他临床疗效之间的有效性,或者通过在临床药物开发阶段分子层面上去预测类似药物的有效性。
金锋(新樾生物):现在缺什么样的数据?其实缺的不是物质本身的数据,缺的是横跨化学和生物之间的数据。实际上是要建立起小分子结构和靶蛋白,以及对整个生物集体关系的数据。为什么会缺?第一点是受生物科学发展的限制;第二是人的主观性。
即日起,蓝驰创投英文品牌变更为「LanchiVentures」,不再与硅谷风险投资基金BlueRunVentures同名共享。
蓝驰创投官方网站同步变更:www.lanchiventures.com
更名公告:https://mp.weixin.qq.com/s/I0aO4bVjfeJgIp_QdRx8hg
倒计时跳转: s